Method
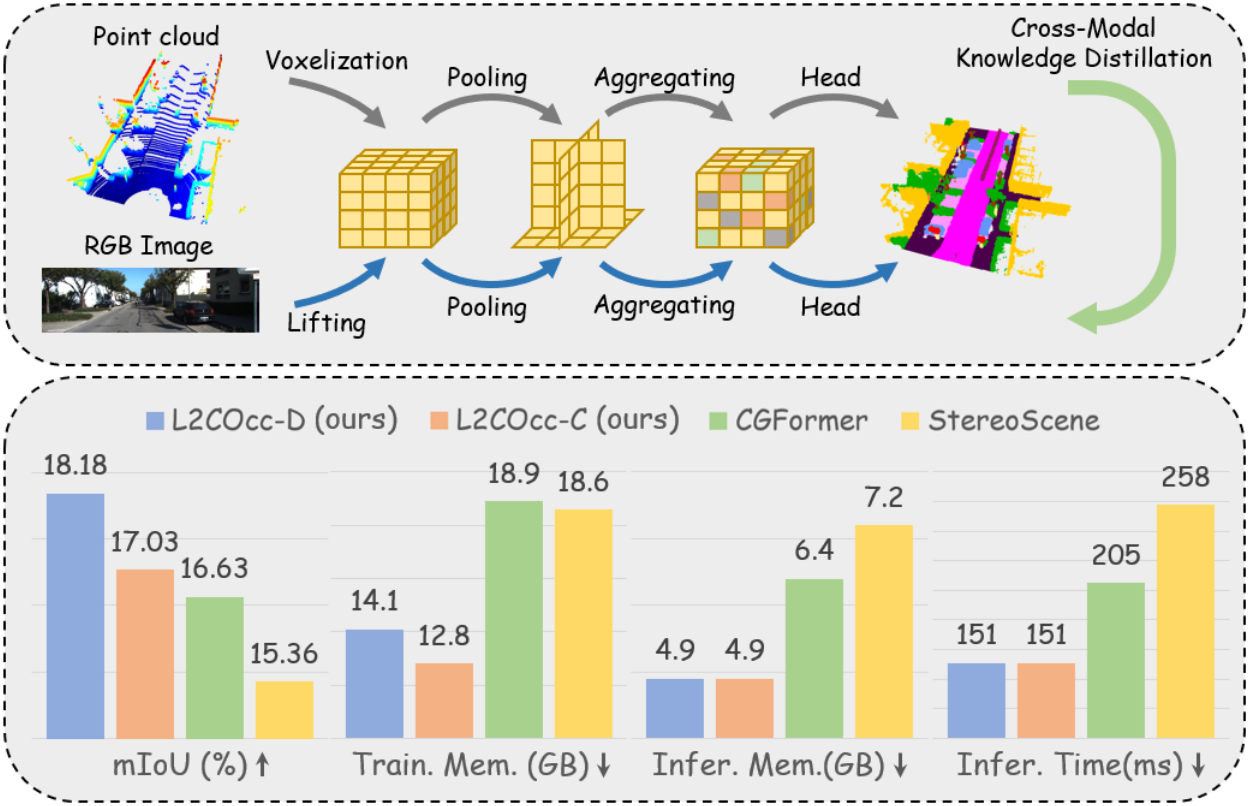
Top: An overview of our framework.
Bottom: Performance of our approach on SemanticKITTI dataset.
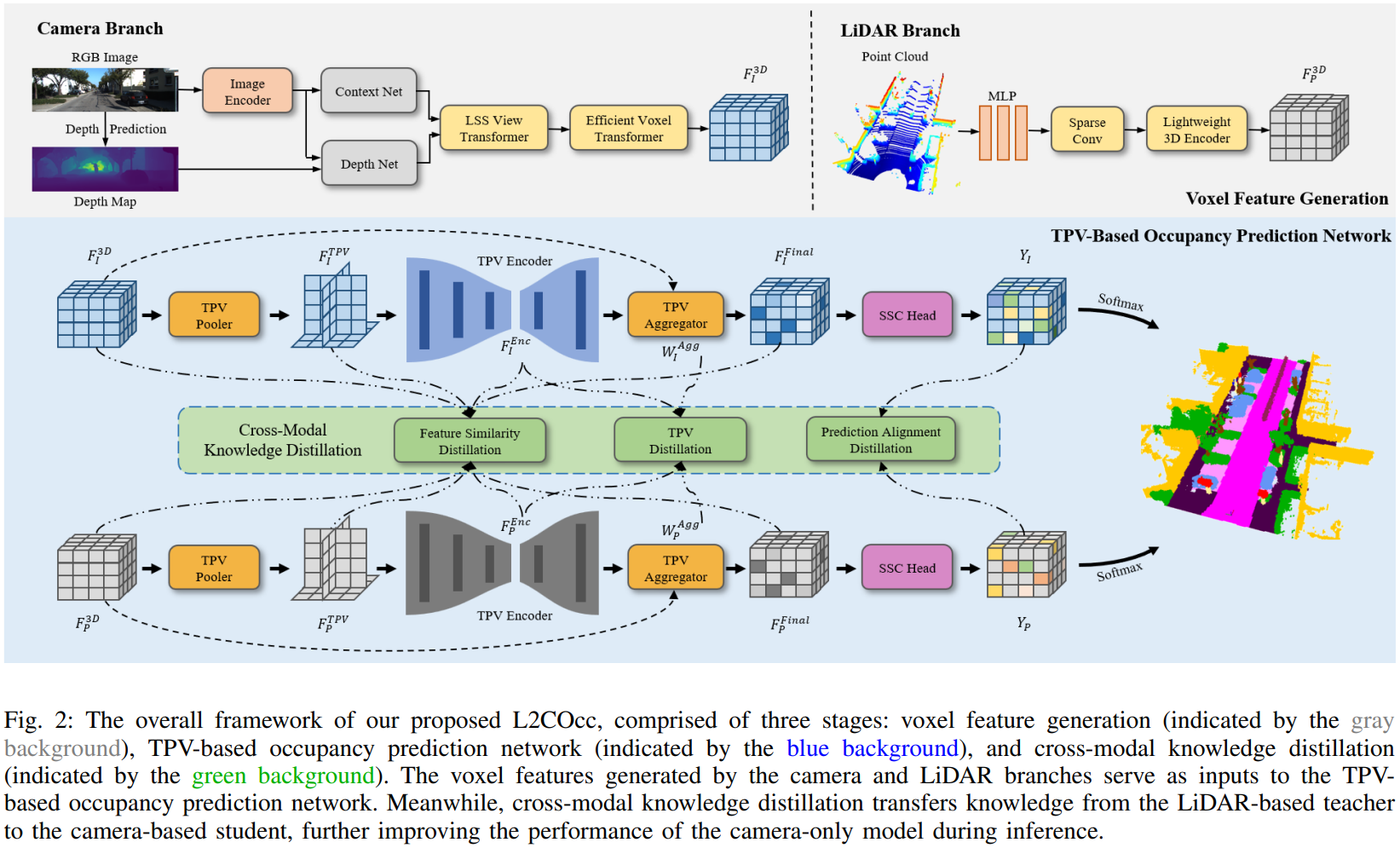
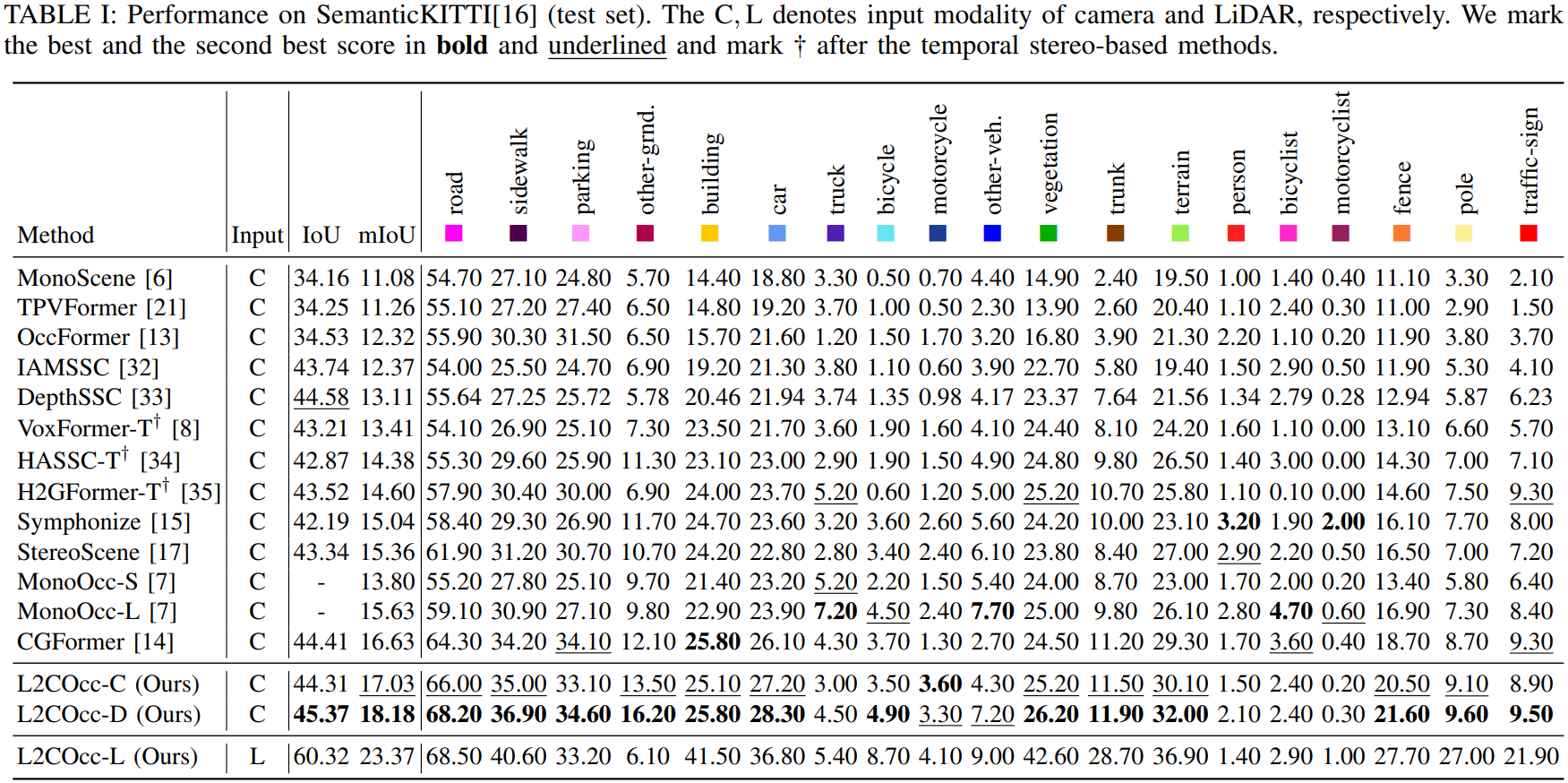
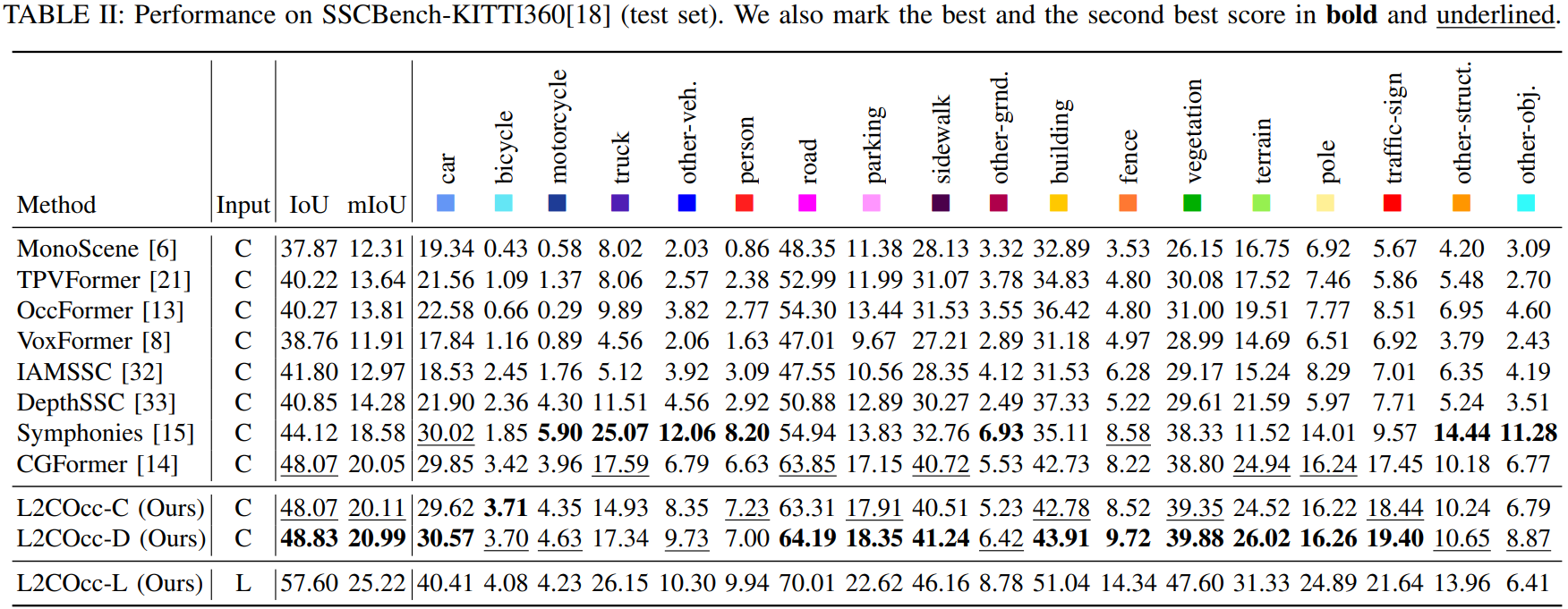
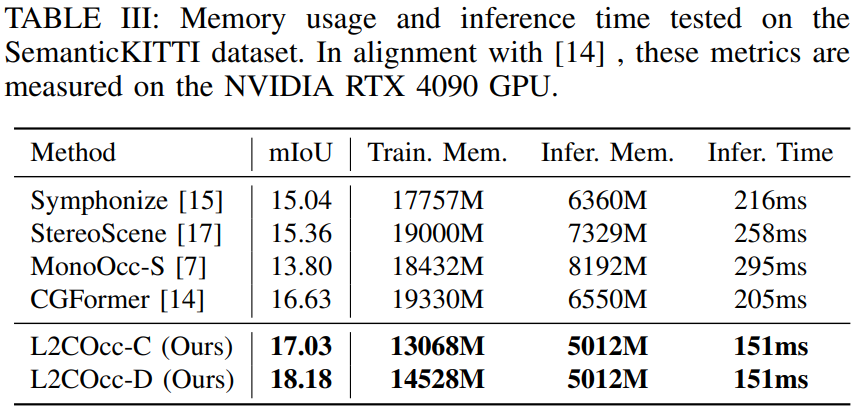
Semantic Scene Completion (SSC) constitutes a pivotal element in autonomous driving perception systems, tasked with inferring the 3D semantic occupancy of a scene from sensory data.To improve accuracy, prior research has implemented various computationally demanding and memory-intensive 3D operations, imposing significant computational requirements on the platform during training and testing.This paper proposes L2COcc, a lightweight camera-centric SSC framework that also accommodates LiDAR inputs.With our proposed efficient voxel transformer (EVT) and three types of cross-modal knowledge modules (FSD, TPVD, PAD), our method substantially reduce computational burden while maintaining high accuracy. The experimental evaluations demonstrate that our proposed method surpasses the current state-of-the-art vision-based SSC methods regarding accuracy on both the SemanticKITTI and SSCBench-KITTI-360 benchmarks, respectively. Additionally, our method is more lightweight, exhibiting a reduction in both memory consumption and inference time by over 23%.
@inproceedings{wang2025l2cocc,
title={L2cocc: Lightweight camera-centric semantic scene completion via distillation of lidar model},
author={Wang, Ruoyu and Ma, Yukai and Yao, Yi and Tao, Sheng and Li, Haoang and Zhu, Zongzhi and Liu, Yong and Zuo, Xingxing},
booktitle={2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
pages={716--723},
year={2025},
organization={IEEE}
}